
日本倾倒核废水,为何没有引起国际社会的大力反对?
【导读】数据造假的三种常见形态!2015年06月2日行业资讯日常生活工作中,处处都会与数据打交道,但你知道数据是会“说谎”的,即你看到的数据结果并不是事实。本文介绍一些常见的说谎场景以及如何避免。一、图表欺骗图表通常用来增强需要文字和数据的说服力,通过可视化的图表更容易让受众接受信息。但图表有时候会表现的不是数据的本质:1.图表拉伸如果没有特殊用途,通常图表的长(横轴)与高(纵轴)的比例为1:1到1:2之...
数据造假的三种常见形态!
2015年06月2日
行业资讯
日常生活工作中,处处都会与数据打交道,但你知道数据是会“说谎”的,即你看到的数据结果并不是事实。本文介绍一些常见的说谎场景以及如何避免。
一、图表欺骗
图表通常用来增强需要文字和数据的说服力,通过可视化的图表更容易让受众接受信息。但图表有时候会表现的不是数据的本质:
1.图表拉伸
如果没有特殊用途,通常图表的长(横轴)与高(纵轴)的比例为1:1到1:2之间,如果在这个范围之外,数据现实的结果会过于异常。比如:
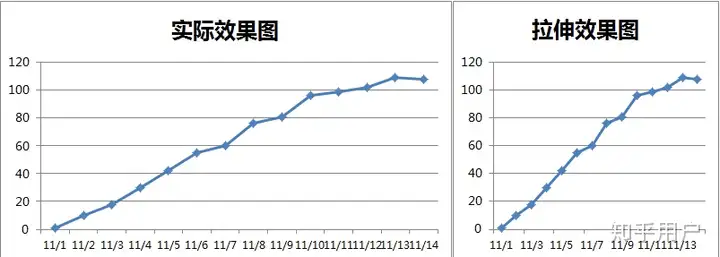
150602095039-1113-0
2.坐标轴特殊处理
在很多场合下,如果两列数据的取值范围差异性过大,通常在显示时会取对数,这时原来柱状图间的巨大差异会被故意缩小。通常,严谨的分析师在讲解之前会进行告知。比如:
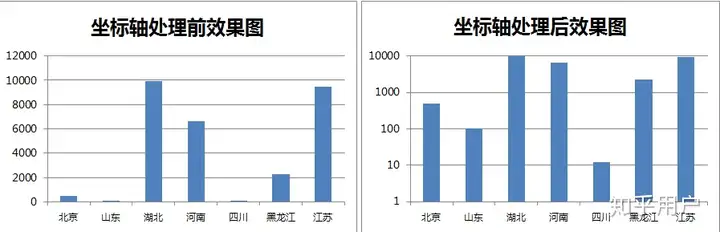
150602095039-4W2-2
3.数据标准化
数据标准化也是一个让数据落在相同区间内常用的方法,常用Z标准化或0-1标准化,如果不提前告知,可能会误以为两列数据取值异常接近,不符合实际业务场景,比如:
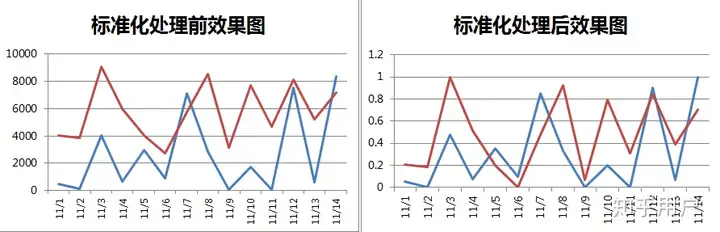
150602095039-5Z2-4
隐秘层次:★★☆☆☆
破解方法:询问分析师的图表各个含义,了解基本图表查看常识。
二、数据处理欺骗
数据处理中的欺骗方法通常包括抽样方法欺骗、样本量不同、异常值处理欺骗等。
1.抽样方法欺骗
整体样本的维度,粒度和取数逻辑相同的情况下,不用的样本抽样规则会使数据看来更符合或不符合“预期”。比如在做用户挽回中,假如做的两次活动的抽样样本分别是最近6个月未购物和最近6个月未购物但有登陆行为的用户,不用做什么测试,基本上可以确定后者的挽回效果更佳。要识破这个“骗局”只需要询问数据取样方法即可,需要细到具体的SQL逻辑。
2.样本量不同
严格来说样本量不同并不一定是故意欺骗,实践中确实存在这种情况。(遇到这种情况可以用欠抽样和过抽样进行样本平衡)样本量不同分为两种情况:
样本量数量不同。比如要做效果差异对比,第一步是做效果比对,假如两个数据样本量分别是几千和几万的级别,可比性就很小。尤其是对于样本分布不均的情况下,数据结果可信度低。
样本主体不同。这是非常严重的数据引导错误,通常存在于为了达到某种结果而故意选择对结果有利的样本。比如做品类推广,一部分用户推广渠道为广告,另一部分是CPS可以遇见相同费用下后者的效果必然更好。
相同样本不同的客观环境。比如做站内用户体验分析,除了用随机A/B测试以外,其他所有测试方法都没有完全相同的客观环境,因此即使选的是相同样本,不同时间由于用户,网站本身等影响,可信度较低。
3.异常值处理欺骗
通常面对样本时需要做整体数据观察,以确认样本数量、均值、极值、方差、标准差以及数据范围等。其中的极值很可能是异常值,此时如何处理异常值会直接影响数据结果。比如某天的销售数据中,可能存在异常下单或行单,导致品类销售额和转化率异常高。如果忽视该情况,结论就是利好的,但实际并非如此。通常我们会把异常值拿出来,单独做文字说明,甚至会说明没有异常值下的真实情况。
隐秘层次:★★★☆☆
破解方法:在跟数据分析师沟通中,多询问他们在数据选取规则,处理方法上的方法,如果他们吞吞吐吐或答不上来,那很有可能是故意为之。同时,业务人员也要增强基本数据意识,不能被这种不可见的底层错误欺骗。
三、 意识上的欺骗
这种欺骗是等级最高也是最严重的欺骗和错误,通常存在于数据分析师在做数据之前就已经下结论,分析过程中只选取有利于证明其论断的方法和材料,因此会在从数据选择,处理,数据表现等各个方面进行事实上的扭曲,是严重的误导行为!数据分析师需要有中立的立场,客观的态度,任何有立场的分析师的结论都会失之偏颇。
隐秘层次:★★★★★
破解方法:在跟该分析师沟通中,查看其是否有明显立场或态度,如果有,那么该警惕;然后通过上面的方法逐一验证。
综上,当你遇到以下数据情形,就需要警惕数据的真实性了:
数据报告从来不注明数据出处,数据时间,数据取样规则,数据取得方法等。现在市场上很多报告都属于这一类。
数据报告在做市场调研中说明全样本共1000,其中北京可能只有100,基于这100个样本出来的结论显然不可信。事实上很多市场研究报告就是这样出来的。
数据报告中存在明显的观点,对于事物的分析只讲其优势或劣势,不全面也不客观。现在很多互联网分析师就是属于这类,大家注意辨别。
PS:本文摘自《中国统计网》
这些只是入门级的数据造假方法,但已经足以让非“专业人士”头痛半天了。
再来看看数据造假方面的经典著作《统计数字会撒谎》的基本内容(美国统计学家达莱尔.哈夫著):
日常工作生活中,有常见的八种误导方式。
1、内在有偏的样本
先从 1949 年的一篇新闻报道说起,报道说,「1924 级的耶鲁毕业生,平均年收入为 25111 美元」。这在当时是一个非常高的收入,会让你感觉,只要把孩子送进耶鲁大学,他的下半生一定富贵。可真是这样吗?
常识告诉我们,25 年后,能够取得联系的人并不多。而且许多人不会回答涉及隐私的问卷。所以这个收入的数据,局限在一个特定的样本上,即能够取得联系,并愿意回答问卷的耶鲁学生。那么,这个样本真的有代表性吗?能代表没联系上,以及没回答的毕业生吗?而且还要假设,他们说的都是真话。也就是说,这个统计样本,是有偏向的。所以,为了确保统计有价值,根据抽样得出的结论,一定要采用具有代表性的样本,即完全遵循随机原则,从总体中选出样本。但因为这样的难度很大,并且十分昂贵,所以目前民意调查和市场研究,会采用分层随机抽样,而分层抽样的规则,会最终影响调查的结果。典型的如美国大选民意调查,往往和结果有较大的误差。所以,看统计结果时,务必要了解它的样本是如何选择的。
2、精心挑选的平均数
平均数的算法,有三种,而且结果完全不一样,但都是正确的算法。以一个小区为例,如果你是房产销售,想让购房人认为,小区住户平均收入很高,那么就会用算术平均数计算平均收入。如果为了降低税率,宣称小区收入低,支付不起各种上涨的费用,那么就会用众数,即出现最频繁的数字。这往往是小区占比最多的低收入人群的收入。而中位数,则在算术平均数和众数之间。
所以对于均值,一定要非常谨慎,避免被误导。
3、没有披露的数据
如某广告标题:「用户反映使用多克斯牌牙膏,将使蛀牙减少 23%」。结论出自一家信誉良好的独立实验室,并且还经过第三方机构证实,听上去是一款非常好的产品。可如果你看下广告下方一排小字,可能写着「被测试用户 12 人」。实际上,绝大多数广告商还会索性将类似的文字删除。如一种叫柯迪斯博士的牙粉,宣传治疗龋齿获得极大成功,可实验仅仅建立在六个案例之上。所以,在被告知某个调查结果时,记得问一句:为了得出这个结论,你调查了多少名被访者?
4、毫无意义的差别
某知名杂志,曾经做过一个不同品牌香烟,尼古丁及其他有害物质的含量的研究,并将结果刊登。得出的结论是,无论你吸什么牌子的香烟,对身体的危害,不会有太大的差异。可是,这篇文章中,有害物质含量排名最后的香烟厂家,却以此调研作为广告,大肆宣称,国家级杂志组织实验表明,自己的香烟有害物质含量排名最后。而研究原文中关于各个品牌的差异并不显著的表述,厂家却只字未提。正如同五十步笑百步,在比较相差不大的数据,大部分时候没有任何的意义。毕竟所有的抽样统计,都会有误差。只有这些差别大到足够有意义时,才能称之为差别。
5、令人惊奇的图形
人们对于数字,似乎有一种天生的畏惧,因而在很多广告中,都会采用画图的方式。最常见的,就是直线图。在显示趋势时,直线图非常有用。书中,用同一组数据,做出了三张看上去完全不一样的图表。如将图表的纵轴,省略一半,会让原来缓慢上升,看上去很平缓的曲线,显得有非常明显上升;如改变横坐标与纵坐标的比例关系,将纵坐标的每一个刻度缩减为原来的 10%,那这时,曲线将上涨得更加猛烈。可见,完全相同的数据,却可以给你带来了完全不一样的视觉幻觉。所以,阅读统计图时,一定要详细了解横坐标和纵坐标的数值。
6、一堆图形的滥用
柱形图是一种非常便捷常用的方法,但是柱形图也具有欺骗性。如 A 国家的收入,是 b 国家的两倍,那么传统的柱形图我们会看到,A 国家柱形的长度,是 b 国家柱形长度的两倍。可是,别有用心的人,会用三维的象形图。由于物体的三维效果,往往变成了 2 乘 2 乘 2,即 8 倍的视觉效果,不经意间,就扭曲了真实。所以,看象形图时,一定要小心,数字是 2:1,可能视觉效果却是 4:1,甚至 8:1。毕竟在大多数的时候,视觉效果起着决定性的作用。
7、不完全匹配的资料
如果你想证明一件事,却发现没有能力办到,那么就试着解释其他相关的事情,并假装它们是一回事,这样很可能会把人唬住。如,美国与西班牙交战期间,美国海军的死亡率是 9‰,而同一时期,纽约市居民的死亡率是 16‰。后来,海军征兵人员,就用这些数据来证明,参军更加安全。 这些统计数据,看上去,似乎还真是这样,可你总觉得似乎有点不对劲,打仗怎么可能死亡率比在城市低?
原因在于,这两组对象根本不具备可比性。海军主要是由那些体格健壮的年轻人组成,而城市居民则包括婴儿、老人、病人这些死亡率较高的群体。两个完全无法比较的数据,并不适合放在一起对比,得出参军更安全的结论。收集不相关资料,把完全不同的两件事混淆在一起,就像挂羊头卖狗肉一样。
8、相关关系的误解
相关关系的误解,是我们常见的一种统计误区,如,英国一座岛屿上的土著居民发现,健康人身上总有一些跳蚤,而那些即将死亡的人身上通常没有跳蚤。于是他们得出结论,跳蚤使人体健康。之后,甚至有人依据这个现象在医学杂志上发表了论文。直到后来,细心的观察者最终发现了真相。原来几乎每个土著居民身上都有跳蚤,只是当人们发烧时,随着体温上升,跳蚤不能承受高温,就离开了。
还有人因为冰淇淋销售数据和溺水死亡人数同步提高,得出结论——冰淇淋销售火爆,会导致溺水死亡的人数显著提高。可事实上,这是因为,夏天时,冰淇淋销量高,同时夏天游泳的人多,溺水死亡的概率大,这两者它并没有相关关系,只是有着相同的趋势而已。
所以,两个事物之间有相同的趋势,并不能用于说明,其中一个将引起另一个的变化。
了解了八种常见的误导方式。接着我们来说第二个要点:统计资料是如何被操纵的。
许多统计资料的歪曲和被控制,并不是资深统计学家所为。而是出自资深统计学家之手的完善资料, 最终被销售人员、营销专家、记者或广告撰稿人扭曲、夸张、简化或刻意地进行挑选。
美国普查局的年度分析中写道,「美国家庭的平均年收入,是 3100 美元」。可是由拉塞尔塞奇基金会发布的一篇新闻中,这个数据却是惊人的 5004 美元。那为什么这个数据跟普查局的数据差距这么大?原来,普查局用的是中位数,这是一种合理的计算方法。而拉赛尔赛奇基金创造了一个假想的家庭,他们将美国居民的总收入除以总人口数,得到人均 1251 美元,所以,一个四口之家的总收入,1251 乘以 4,5004 美元。
这种奇怪的算法,在两个方面进行了夸张,一方面,他使用的算术平均数,而不是更具代表性、偏差相对较小的中位数;另一方面,他假设家庭的收入和人口数成正比,实际上,四口之家的财富绝不一定是两口之家的两倍。 这也正如我们之前所说的,对那些未加解释的平均数,一定要谨慎。
为了使最声名狼藉的统计资料,看上去更有分量,更精确,小数的使用也能骗取人们的信任感。如询问 100 个人昨晚的睡眠时间,然后宣布人们平均每天睡眠 7.831 小时。听上去就给人非常专业的感觉。可如果你说 7.8 小时,或差不多 8 小时,就失去动人的准确性。即使这点差距,并没有什么意义。
此外,百分数也给误解提供了肥沃的土壤,和小数一样,它也能为不确切的事物,蒙上仿佛精确的面纱。如「现在就购买你的圣诞礼物,你将节省 100%」,这则广告,听上去就像圣诞老人免费的馈赠,但实际上它混淆了比较的基础,相对于原来的价格,价格只缩减了 50%。虽然对于打折后的价格而言,减少量确实是 100%。但这与广告上的内容可不一样。这就是变换基数所产生的幻觉。
此外,将一些看似能直接相加,却不能这样操作的事情加在一起,会产生大量的欺骗和隐瞒。如《纽约时报》书评有这么一段,种植和加工成本在最近十年上升了 10%-12%,材料成本攀升了 6%-9%,销售及广告成本上升了 10% 以上,将所有这些加起来的话,总成本至少上升了 33%。听上去很有说服力。可是换个角度想下,你要买的东西,涨价了 5%,你买了 20 个,难道一共要多付了 100%?
统计不仅是科学,还是一门艺术。统计方法的选择会影响我们对事物的判断,数据是否合理使用也依赖统计工作者的意志。但在商业活动中,统计工作者不大可能选择不利于自己的方式,就像撰稿人在描述赞助商的产品时,不会使用「易碎,价格低贱」的字眼,而是会说「轻便,经济实惠」。
说完第二个要点,我们总结一下:各种统计操作,在我们的日常工作生活中非常普遍,我们在报纸、杂志和书籍中看到统计资料、结论以及数据时,应该经过认真地思考后再接受他们。
那么接下来我们就说第三个要点, 怎样凭双眼就能识破虚假的统计资料,并揭开他们的老底。这只需要通过五个问题。
1、谁说的?
首先要寻找的是偏差。出于学术,名誉和收入的考虑,统计数据工作者,都有可能产生偏差。有些是有意识的偏差,这种偏差可能是错误的陈述,可能是不易被揭穿的含糊之辞。其次测量标准的改动和使用不正确的测量方法等都会产生偏差。当某个权威人士被引用时,要弄清楚到底是因为资料内容确实符合,还是仅仅是要扯上权威人士的大名。
2、他是如何知道的?
我们需要知道这些统计数据是如何产生的?如样本是否有偏,样本是否足够大,从而能解释问题?观察值是否足够多,从而能保证结论的可靠性。
3、遗漏了什么?
通常你并不会被告知包含了多少观测值,特别是当信息来源于与信息存在利害关系的一方时。当均值与中位数相差甚远时,需要注意那些没有标明类型的平均值。很多数据因为没有比较,而变得缺乏意义。有时仅给出百分数,却缺少原始数据,也能造成欺骗。看到一个指数时,你或许应该关心,指数的基期是什么。
4、是否有人偷换了概念?
在分析统计资料时,请留心从搜集原始资料到形成结论的整个过程,是否存在概念的偷换。正如疾病案例的增多,不能等同于发病率提高。民意调查中的获胜也并不等同于竞选时的获胜。读者对全球时事文章的偏爱也并不说明,如果杂志刊登此类文章会提高杂志销售量。此外,数据统计口径的变化,也会形成概念偷换的效果。
5、这个资料有意义吗?
如果接触到的资料是建立在未经证实的假设基础之上,你需要发问,这个数据是否有意义。 20 世纪 50 年代,《社会保障法》修正案的听证会上,有一个争论是,既然预期寿命大约只有 63 岁,将社会保障计划中的退休年龄规定为 65 岁是惺惺作态。可当时,美国的这个年龄数据,是根据 1934-1941 年的生命周期表计算的,当时还是二战期间,而且也已经过时了。实际的平均年龄,早就超过了 65 岁。
上面为你讲的是这本书的第三个要点,即看到任何统计数据,尤其是需要由此作出重大决策时,不妨从这五个问题入手,避免被错误的数据忽悠。
大家可以根据这篇著作给出的的情况试着分析一下,那几个替日方洗白的高赞答案有什么问题,不过对于非专业人员来说这同样是让人颇感挠头的事情,何况这里面还牵扯到政治因素,普通人确实不好过问。
而这次的事件也再一次印证:推崇和狐假虎威,真的经常是看上去一模一样的。
但是,借老虎来吓唬其它动物的“狐狸”,如果居然觉得自己就是老虎,那么一旦老虎发怒,被先吃掉的一定是在老虎嘴边的自己,而不是那些被吓跑的动物。
既然“科学”现在被捧得如此之高,那么就应该知道,它一旦发怒的后果是怎么样的。否则这种需要它时把它推上神坛,却实际上不把它放在眼里的行为,迟早要付出极为惨重的代价。
免责声明:该文由项目方自行发布,玉竹加盟网仅作为信息展示平台,以上信息不代表玉竹加盟网的观点和立场。市场存风险,投资需谨慎!
请填写或选择常见问题
- 项目很好,请尽快联系我详谈。
- 请问我所在的地区有加盟商了吗?
- 我想详细的了加盟流程,请联系我!
- 留下邮箱,请将详细资料邮件给我
- 代理/加盟鱼你相伴能得到哪些支持?
相关动态
- • 原创 07/08
- • 跑男4将收官,各品牌娱乐营销 07/08
- • 《奔跑吧》今晚开播!方特再携 07/08
- • 哥哥救人牺牲,14年后妹妹做 07/08
- • 哥哥救人牺牲,14年后妹妹继 07/08
- • 原创 07/08
- • 原创 07/08
- • 原创 07/08
- • 郑渊洁老着老着却出圈了,回答 07/08
- • 国产动漫《沧元图》开播,且看 07/08
- • 名家写高考作文丨王选:写给哥 07/08
- • 女孩到大公司面试,不料总裁竟 07/08
- • 大雨暴雨!雷暴大风!即将抵达 07/08
- • 《寄生虫》贫富差距下的社会缩 07/08
- • 韩国电影的高光时刻,荒诞感十 07/08
- • 「寄生虫」删掉的十分钟 07/08
- • 寒冷的冬天里,主人应该注意的 07/08
- • 5本畅销玄幻小说推荐!诡秘、 07/08
- • 商务部:1-5月我国服务进出 07/08
- • 2019年大神新作,让你一年 07/08